Definition
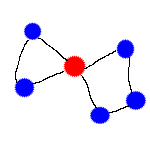
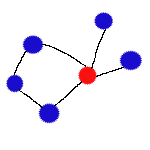
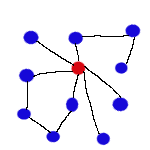
Connected graph -- A graph which each node can reach all other nodes via edges.
Cluster of genes -- A biological term refering to a connected graph of genes.
Bridges -- In Computer Science sense it should be called articulation point, but in the field of biology
we use the term "bridge" to refer to the same thing. Bridges are nodes that if removed, would generate
disconnected graphs.
Type of bridges X, Y and Z -- Removing a "X" bridge leads to formation of two or more connected graphs.
Removing a "Y" bridge leads to formation of one connected graph and one or more single nodes.
Removing a "Z" bridge leads to more than one connected graphs and more than one single nodes. (
Notice: definitions here are not onto)